I am a PhD student at the College of William and Mary advised by Antonio Mastropaolo. I am also fortunated to be mentored by Anh Totti Nguyen, Truong-Son Hy, and Thiago Serra.
I am interested in multimodal AI and trustworthy AI: (1) evaluating and understanding LLMs/MLLMs and (2) making AI systems more robust and interpretable in high-stakes domains such as healthcare.
I was a Machine Learning Research Intern at CodaMetrix (Summer 2024 & 2025), where I developed LLM agents to (1) extract medical entities from EHRs and (2) evaluate and correct entities extracted by human experts and LLMs.
Selected Publications
♠ denotes equal contribution
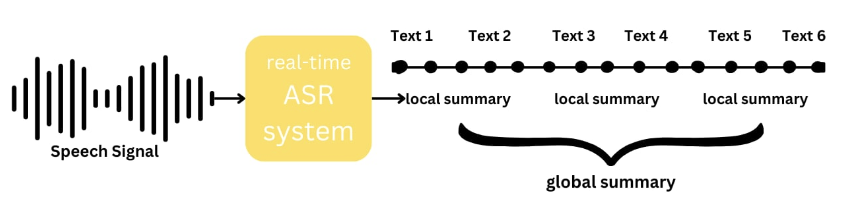
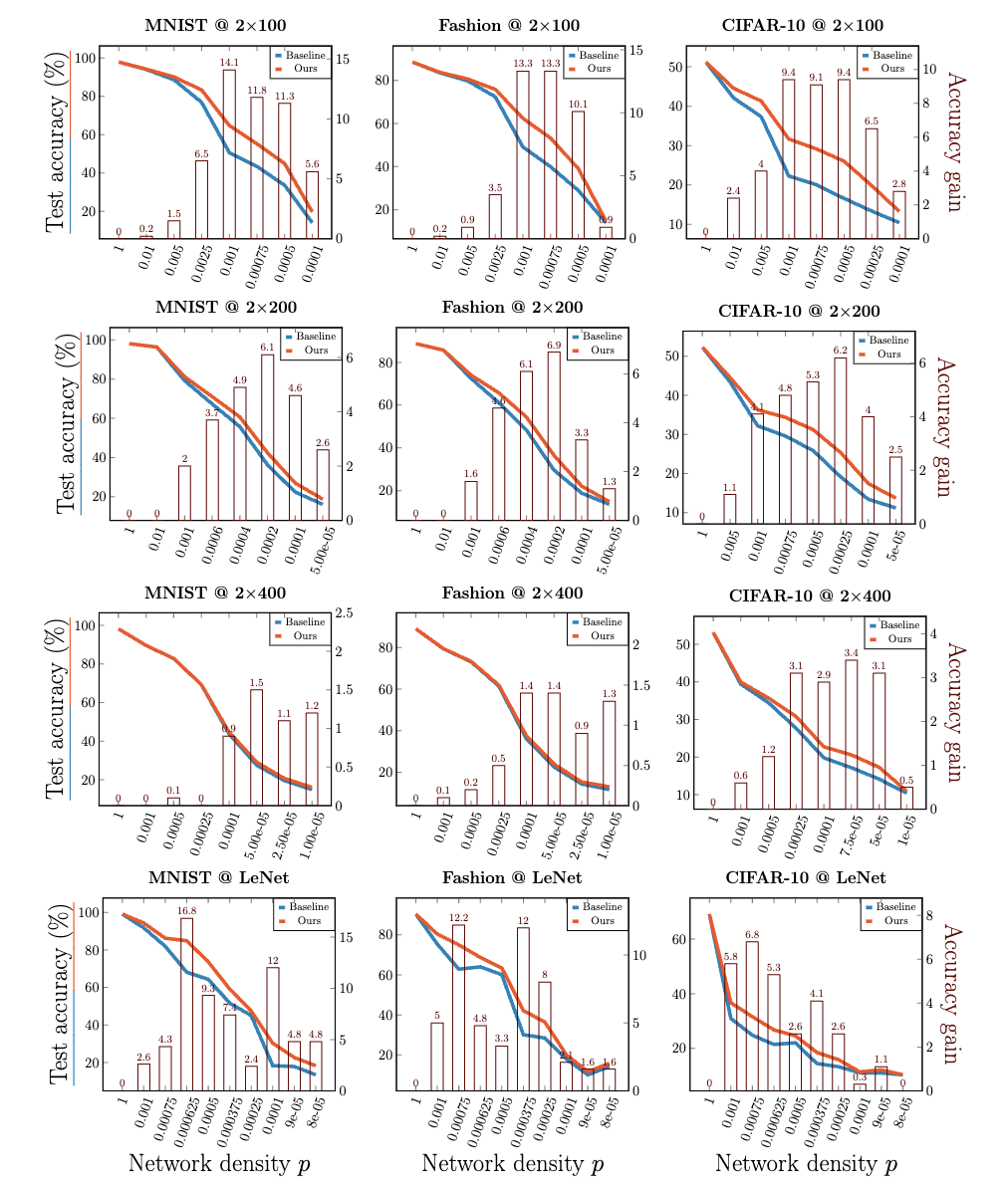
Selected Preprints